ProtoBuf 语法和编码原理入门
序列化是指将结构化数据转换成易于存储或发送的数据格式的过程,Protocol Buffer 简称 ProtoBuf,是一种语言无关,平台无关的序列化工具,由谷歌在 2008 年开源。相较于常见的序列化工具 XML, JSON, YAML, CSV 等,ProtoBuf 的优势主要包括序列化后数据量小,序列化和反序列化过程速度快,使用时只需定义 proto 文件使得其维护成本低,可向后兼容等;但因为其数据以二进制数据流的形式存在,也有人类不可读的劣势。
本文主要介绍 ProtoBuf 的使用方法,包括 .proto 文件的语法,以及如何使用 protoc 工具来生成不通语言的代码;以及其编码原理。
1 语法
首先从 https://github.com/protocolbuffers/protobuf 找到最新版本的 ProtoBuf,下载预编译好的二进制文件 protoc 解压到环境变量目录,本文使用的是 3.15.7 版本:
$ protoc --version
libprotoc 3.15.7
以一个简单的 proto 文件为例,它的语法和 C++ 类似:
// msg.proto
syntax = "proto3";
package Message;
message SearchRequest {
reserved 6, 9 to 12;
reserved "foo", "bar";
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
}
message ResultType {
message Result {
string url = 1;
string title = 2;
repeated string snippets = 3;
}
}
message SearchResponse {
repeated ResultType.Result results = 1;
}
使用 protoc 工具生成指定语言的代码:
protoc --proto_path=./ --go_out=./go_out/ --cpp_out=./cpp_out/ msg.proto
其中 --proto_path 或 -I 用于参数指定生成所需的 proto 文件和被导入的 proto 文件所在的目录,不指定的话默认为当前目录;go_out 和 cpp_out 分别为生成的 go 文件和 cpp 文件指定目录;最后是我们所需要转换的所有 proto 文件;更多的参数可以输入 protoc --help 查看。
1.1 数据结构
msg.proto 文件里包含了两部分内容:首先需要指定 ProtoBuf 的版本为 proto3,不指定的话编译器则会默认使用老版本的 proto2 语法;然后是定义我们所需要的 message 类型。message 类型中有很多字段,每个字段都对应一个独一无二的编号,这些编号是用来在序列化后的二进制数据流中识别字段用的。
字段和编号
字段(field)分为两种类型:
- 唯一的(singular):字段的默认类型,这样的字段对应的数据只能是 0 个或 1 个;
- 重复的(repeated):类似于数组,这样的字段对应的数据可以有任意多个,并且会保留其顺序。
在将字段对应到编号(number)上时,需要注意以下几点:
- 我们可以使用 [1, 19000) 和 (19999, 2^29 - 1] 区间内的任意编号用来标识字段,中间 [19000, 19999] 是为 ProtoBuf 的实现所预留的;
- 在对 proto 文件进行编码时,编号 1 到 15 需要占用 1 个字节,16 到 2047 需要占用 2 个字节,因此一般会将常用的字段对应到编号 1 到 15上以节约空间;
- 一旦使用了某个编号就不能修改其对应字段的类型了,否则会造成无法兼容的问题。
组合和嵌套结构
我们可以直接在一个 message 类型里直接嵌套声明并使用另一个 message 结构:
message SearchResponse {
message Result {
string url = 1;
string title = 2;
repeated string snippets = 3;
}
repeated Result results = 1;
}
如果要使用在另一个 message 类型里嵌套声明的子 message 类型,则需要在定义时加上其父 message 类型的名称:
message ResultType {
message Result {
string url = 1;
string title = 2;
repeated string snippets = 3;
}
}
message SearchResponse {
repeated ResultType.Result results = 1;
}
类似的,我们也可以以组合的方式在一个 message 类型里引入另一个 message 类型作为字段,并为其赋予 repeated 属性;如果引入的 message 类型在另一个 proto 文件中则需要 import 对应的文件:
// msg.proto
import "result.proto";
message SearchResponse {
repeated Result results = 1;
}
// result.proto
message Result {
string url = 1;
string title = 2;
repeated string snippets = 3;
}
import
import 的方式有两种,一种是以相对路径的方式 import,如上面的例子;另一种是在使用 protoc 工具生成代码时使用 -I 指令指定所需要包含的 proto 文件所在的目录,并以绝对路径的方式 import:
$ tree
.
|-- msg.proto
`-- result
`-- result.proto
1 directory, 2 files
$ protoc -I. -I./result/ --go_out=./ msg.proto
1.2 关键字
包
包(package)的功能很简单,类似于 C 语言中的 namespace,它可以用来避免不同的 ProtoBuf 消息之间的命名冲突:
package Message;
服务
服务(service)是用来定义 RPC 所使用的消息类型的,在 gPRC 有非常充分的应用,它的定义和 Go 的函数定义比较类似:
service SearchService {
rpc Search (SearchRequest) returns (SearchResponse);
}
选项
选项(option)可以改变 proto 文件中某些预定义上下文的处理方式,包括但不限于:
optimize_for修改代码生成的方式,有SPEED高度优化,CODE_SIZE减少代码,以及LITE_RUNTIME精简功能三种类型;packed针对 repeated 类型的字段,生成更紧凑的代码;deprecated针对字段,表明已经废弃,一般只会生成注释,应该尽量搭配reserved关键字使用。
option optimize_for = CODE_SIZE;
// ...
repeated int32 samples = 4 [packed=true];
int32 old_field = 6 [deprecated=true];
版本兼容
为了使得新版本的 proto 文件能够兼容老版本的,我们不能修改任何已有字段的类型,防止在使用以往版本的老代码在解析新版本的数据结构时发生兼容性问题。
当我们不再使用某些字段时,我们可以将字段及其对应的编号都删除或注释掉;为了防止我们不小心再次使用相同的编号并将其对应到不同类型的字段上,我们可以使用 reserved 关键字来对已经被删除的字段和编号进行标注,让编译器在编译时检查这些字段和编号是否有被再次使用:
// msg.proto
message SearchRequest {
reserved 3, 6, 9 to 12;
reserved "foo", "bar";
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
}
$ protoc -I. --go_out=./ msg.proto
msg.proto: Field "result_per_page" uses reserved number 3.
1.3 数据类型
基础类型
下面的列表列出了 proto 文件中可以使用的所有基础数据类型
| 类型 | 默认值 | 说明 | C++ 类型 | Python 类型 | Go 类型 |
|---|---|---|---|---|---|
| double | 0 | double | float | float64 | |
| float | 0 | float | float | float32 | |
| int32 | 0 | 使用 varint 编码,因此如果有负数建议使用 sint32 | int32 | int | int32 |
| int64 | 0 | 使用 varint 编码,因此如果有负数建议使用 sint64 | int64 | int/long[3] | int64 |
| uint32 | 0 | 使用 varint 编码 | uint32 | int/long[3] | uint32 |
| uint64 | 0 | 使用 varint 编码 | uint64 | int/long[3] | uint64 |
| sint32 | 0 | 使用 varint 编码,有符号 | int32 | int | int32 |
| sint64 | 0 | 使用 varint 编码,有符号 | int64 | int/long[3] | int64 |
| fixed32 | 0 | 固定 4 字节,如果数值超过 228 则比 uint32 效率更高 | uint32 | int/long[3] | uint32 |
| fixed64 | 0 | 固定 8 字节,如果数值超过 256 则比 uint64 效率更高 | uint64 | int/long[3] | uint64 |
| sfixed32 | 0 | 固定 4 字节 | int32 | int | int32 |
| sfixed64 | 0 | 固定 8 字节 | int64 | int/long[3] | int64 |
| bool | false | bool | bool | bool | |
| string | "" | 必须以 UTF-8 或 7位 ASCII 编码,长度不能超过 232 | string | str/unicode[4] | string |
| bytes | "" | 长度不超过 232 的任意字节序列 | string | str | []byte |
除了这些基础类型之外,枚举类型(enums)的默认是 0(也就是定义的第一个枚举值),repeated 字段的默认值为空。
map
ProtoBuf 的一大亮点就是内置了 map 数据类型,其 key_type 可以是任意整数类型或字符串类型:
map<key_type, value_type> map_field = N;
map 目前不能被 repeated 修饰,但可以通过自定义一个类似于 map 的结构来实现其效果,需要自行解决从 key_type 到 value_type 的映射关系:
message MapFieldEntry {
key_type key = 1;
value_type value = 2;
}
repeated MapFieldEntry map_field = N;
枚举类型
proto 文件中的枚举类型定义大致如下:
message EnumRequest {
enum Corpus {
option allow_alias = true;
UNIVERSAL = 0;
WEB = 1;
NET = 1;
IMAGES = 2;
LOCAL = 3;
}
Corpus corpus = 1;
}
在使用枚举类型时需要注意几点:
- 枚举值定义必须在 32 位整数整数范围内,并且不建议使用负数(因为枚举值在序列化时使用 varint 编码);
- 在枚举类型的定义中必须有一个值为 0 的枚举变量;
- 如果要定义值相同的枚举类型,必须加上
option allow_alias = true。
特殊类型
除了 double, float, int32 等基础数据类型,proto 文件里还可以定义一些特殊的数据类型:
Any包含任意字节数的序列化消息;Oneof类似于union,表示多个字段共享同一块内存,并且只有其中一个能够被赋值;
2 编码过程
ProtoBuf 的编码过程分为两部分:先对字段的定义进行编码,以便在解码过程中识别其类型;再对数据的值进行编码,对其进行压缩。其中第一部分实际上是使用一定的规则对字段的类型和编号进行编码,得到字段的标签 Tag,而并没有用到字段的名字,因此在实际使用中即使修改字段的名字也是不会发生兼容性问题的;第二部分则是使用不同的算法对不同类型的数据进行压缩得到值 Value,主要用到的两种算法分别是 Varint 和 ZigZag。将这两部分编码完成后,再将标签 Tag,字节长度 Length(只有变长类型需要),值 Value 拼接在一起,就得到了编码后的二进制数据。
2.1 标签编码
对标签的编码步骤是先将字段类型映射到一个数字 wire_type 上,再将字段编号 field_num 向左位移 3 位,并将两者进行或操作,即 (field_number << 3) | wire_type。字段类型和 wire_type 的映射关系如下:
| wire_type | 含义 | 存储结构 | 对应的字段类型 |
|---|---|---|---|
| 0 | 使用 Varint 压缩 | [Tag Value] | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | 64 位 | [Tag Value] | fixed64, sfixed64, double |
| 2 | 按长度区分 | [Tag Length Value] | string, bytes, embedded messages, packed repeated fields |
| 3 | Start group | groups (弃用) | |
| 4 | End group | groups (弃用) | |
| 5 | 32 位 | [Tag Value] | fixed32, sfixed32, float |
解码时为了能够获取存储结构的定义,必须提供正确的 proto 文件。
举个例子,假设要对一个字段编号 field_number = 2,字段类型为 sint64 的字段进行编码,它的 wire_type = 0,能够知道 (field_number << 3) | wire_type = 10000,即编码后得到 10;

类似的,在解码时会先取其后三位 & 111 得到 wire_type = 0,再向右位移 3 位得到 field_number = 2。
总结一下,对于字段编码后的字节,后三位表示类型,前置位表示字段编号。
2.2 Varint
对 WireType == 0 的整数类型的主要编码方式是使用 Varint,使用 Varint 编码后的二进制数据长度是不固定的,数值越小的数字编码后的字节长度越小。其步骤分为 3 步:
- 对于一个数字的二进制位表示,将其拆分为 7 个一组的字节;
- 在每一组的头部添加一个最高有效位(most significant bit),只有最大一组有 msb = 0,其他组的 msb 都等于 1;
- 按照小端序排列这些字节。
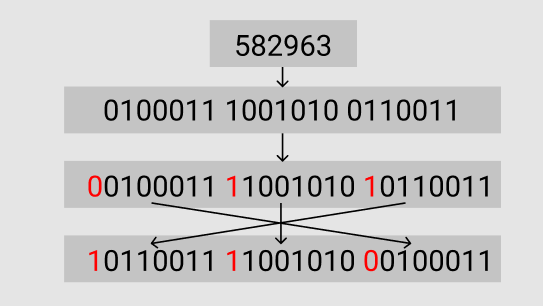
举一个简单的例子,对于数字 582963 来说:
- 它的二进制表示是 10001110010100110011,将其拆分为三组,分别是 0100011, 1001010, 0110011,即 35, 74, 51;
- 在最大的一组前加上最高有效位 0,得到 00100011,仍然是 35;在其他组前加上最高有效位 1,得到 11001010,10110011,分别是 202, 179;
- 将这三个字节按小端序排列,得到 10110011 11001010 00100011,分别是 179, 202, 35,即通过 Varint 编码最后得到的结果。
用 ProtoBuf 对数字 582963 进行编码测试:
message SingleNumber {
int32 Num = 1;
}
func main() {
sn := SingleNumber {
Num: 582963,
}
bytes, err := proto.Marshal(&sn)
if err != nil {
panic(err)
}
fmt.Println(bytes)
}
得到的结果与上述步骤相同,其中第一个字节 8 是对字段进行编码得到的 key:
$ go run main.go msg.pb.go
[8 179 202 35]
解码过程也是类似的:
func main() {
b := []byte{8, 179, 202, 35}
var sn SingleNumber
err := proto.Unmarshal(b, &sn)
if err != nil {
panic(err)
}
fmt.Println(sn.GetNum())
}
$ go run main.go msg.pb.go
582963
2.3 ZigZag
Varint 编码的本质在于去掉数字二进制表示的前置 0 从而减少数据所占用的字节数;而对于用补码表示的负数来说,使用 Varint 进行编码的话,32 位的数字会占用 5 个字节,64 位的数字会占用 10 个字节,效果就显得非常差了。对此 ProtoBuf 采用了 ZigZag 来进行优化,ZigZag 可以将有符号整数映射为无符号整数;正数的编码结果相当于将其乘以 2,负数的编码结果相当于将其绝对值乘以 2 并减 1,编码后的值对应的原始数据在正负数之间摇摆,如下表:
| 原始的有符号整数 | 编码后的无符号整数 |
|---|---|
| 0 | 0 |
| -1 | 1 |
| 1 | 2 |
| -2 | 3 |
| 2147483647 | 4294967294 |
| -2147483648 | 4294967295 |
它的过程也非常简单:
- 假设被编码数的二进制表示是 num,将 num 左移 1 位得到 x
- 将 num 右移 31 位(num 本身的位数 - 1)得到 y,即用符号位覆盖 num 的每一位
- 将 x 和 y 进行异或操作,得到结果
z = x ^ y
举个例子,对于正数 5:
- x = 5 « 1 = 00000000 00000000 00000000 00001010
- y = 5 » 31 = 00000000 00000000 00000000 00000000
- z = x ^ y = 00000000 00000000 00000000 00001010,得到 10
对于负数 -5:
- x = -5 « 1 = 11111111 11111111 11111111 11110110
- y = -5 » 31 = 11111111 11111111 11111111 11111111
- z = x ^ y = 00000000 00000000 00000000 00001001,得到 9
在 ProtoBuf 中,负数会先用 ZigZag,再用 Varint 进行编码,达到进一步压缩数据的效果。
2.4 其他编码过程
变长类型
对于 WireType == 2 的变长类型(string, bytes 等)来说,其序列化后的二进制数据流是以 [Tag Length Value] 的方式存储的,其中 Length 是变长部分的长度,例如:
message SingleNumber {
int32 Num = 1;
string Str = 2;
}
func main() {
sn := SingleNumber {
Num: 582963,
Str: "helloworld"
}
bytes, err := proto.Marshal(&sn)
if err != nil {
panic(err)
}
fmt.Println(bytes)
}
$ go run main.go msg.pb.go
[8 179 202 35 18 10 104 101 108 108 111 119 111 114 108 100]
在输出的结果中,第五个字节 18 是 string Str = 2 的 Tag,其中 field_num = 2, wire_type = 2;第六个字节 10 代表这个变长类型的 Length,即从第七个字节到第十六个字节都是存储的 Value,每一个值均是用 ASCII 码存储的字符。
固定长度类型
对于 WireType == 1 或 WireType == 5 的固定长度类型(fixed32, fixed64 等)来说,其序列化后的二进制数据的长度固定为 4 或 8 个字节,例如:
message SingleNumber {
int32 Num = 1;
string Str = 2;
fixed32 A = 3;
fixed64 B = 4;
float C = 5;
}
func main() {
sn := SingleNumber {
// Num: 582963,
// Str: "helloworld",
A: 256,
B: 257,
}
bytes, err := proto.Marshal(&sn)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(bytes)
}
$ go run main.go msg.pb.go
[29 0 1 0 0 33 1 1 0 0 0 0 0 0]
得到的结果中第 1 个字节是 fixed32 A = 3 的 tag,其中 field_num = 3, wire_type = 5,其后的 4 个字节按照字节序直接存储;第 5 个字节是 fixed64 B = 4 的 tag,其中 field_num = 4, wire_type = 1,其后的 8 个字节同样是按照字节序直接存储的。