Python 源码学习(4):编译器和虚拟机
Python 是一种解释型语言,一般在使用前我们会从 Python 官方网站上下载使用 C 语言开发编译的 CPython 解释器,本文用到的源码均来自 CPython。
Python 解释器(Python Interpreter)由 Python 编译器(Python Compiler)和 Python 虚拟机(Python Virutal Machine)两部分组成。当我们通过 Python 命令执行 Python 代码时,Python 编译器会将 Python 代码编译为 Python 字节码(bytecode);随后 Python 虚拟机会读取并逐步执行这些字节码。
1 Python 编译器
1.1 代码对象
Python 提供了内置函数 compile,可以编译 Python 代码并生成一个包含字节码信息的对象,举例如下:
# test.py
def Square(a):
return a * a
print(f"result:\t\t{Square(5)}")
# main.py
f = "test.py"
code_obj = compile(open(f).read(), f, 'exec')
exec(code_obj)
print(f"code_obj:\t{code_obj}")
print(f"type:\t\t{type(code_obj)}")
$ python3 main.py
result: 25
code_obj: <code object <module> at 0x7f052c156b30, file "test.py", line 1>
type: <class 'code'>
可以看到生成的 code_obj 对象的类型是 class 'code',它在源码中对应的结构体是代码对象 PyCodeObject;代码对象是后续步骤中 Python 虚拟机操作的核心,它将字节码相关的参数个数、局部变量、变量名称、指令序列等信息包装成了一个结构体:
// Include/cpython/code.h
/* Bytecode object */
struct PyCodeObject {
PyObject_HEAD
int co_argcount; /* #arguments, except *args */
int co_posonlyargcount; /* #positional only arguments */
int co_kwonlyargcount; /* #keyword only arguments */
int co_nlocals; /* #local variables */
int co_stacksize; /* #entries needed for evaluation stack */
int co_flags; /* CO_..., see below */
int co_firstlineno; /* first source line number */
PyObject *co_code; /* instruction opcodes */
PyObject *co_consts; /* list (constants used) */
PyObject *co_names; /* list of strings (names used) */
PyObject *co_varnames; /* tuple of strings (local variable names) */
PyObject *co_freevars; /* tuple of strings (free variable names) */
PyObject *co_cellvars; /* tuple of strings (cell variable names) */
/* The rest aren't used in either hash or comparisons, except for co_name,
used in both. This is done to preserve the name and line number
for tracebacks and debuggers; otherwise, constant de-duplication
would collapse identical functions/lambdas defined on different lines.
*/
Py_ssize_t *co_cell2arg; /* Maps cell vars which are arguments. */
PyObject *co_filename; /* unicode (where it was loaded from) */
PyObject *co_name; /* unicode (name, for reference) */
PyObject *co_lnotab; /* string (encoding addr<->lineno mapping) See
Objects/lnotab_notes.txt for details. */
void *co_zombieframe; /* for optimization only (see frameobject.c) */
PyObject *co_weakreflist; /* to support weakrefs to code objects */
/* Scratch space for extra data relating to the code object.
Type is a void* to keep the format private in codeobject.c to force
people to go through the proper APIs. */
void *co_extra;
/* Per opcodes just-in-time cache
*
* To reduce cache size, we use indirect mapping from opcode index to
* cache object:
* cache = co_opcache[co_opcache_map[next_instr - first_instr] - 1]
*/
// co_opcache_map is indexed by (next_instr - first_instr).
// * 0 means there is no cache for this opcode.
// * n > 0 means there is cache in co_opcache[n-1].
unsigned char *co_opcache_map;
_PyOpcache *co_opcache;
int co_opcache_flag; // used to determine when create a cache.
unsigned char co_opcache_size; // length of co_opcache.
};
其中比较重要的成员有两个,分别是编译后生成的指令序列 co_code 和执行当前代码块所需的栈空间大小 co_stacksize。
1.2 字节码
在所有的这些成员变量中,PyObject *co_code 存储了编译后生成的指令序列,它是以字节的方式存储的:
# test.py
def Square(a):
return a * a
print(f"result:\t\t{Square(5)}")
# main.py
f = "test.py"
code_obj = compile(open(f).read(), f, 'exec')
print(f"code obj:\t{code_obj}")
print(f"stack size:\t{code_obj.co_stacksize}")
result = exec(code_obj)
bytecode = code_obj.co_code
print(f"bytecode:\t{bytecode}")
$ python3 main.py
code obj: <code object <module> at 0x7f26cea5ab30, file "test.py", line 1>
stack size: 4
result: 25
bytecode: b'd\x00d\x01\x84\x00Z\x00e\x01d\x02e\x00d\x03\x83\x01\x9b\x00\x9d\x02\x83\x01\x01\x00d\x04S\x00'
我们可以使用 Python 内置模块 dis 来将这些字节码反编译成类似于汇编语言的格式:
import dis
dis.dis(bytecode)
0 LOAD_CONST 0 (0)
2 LOAD_CONST 1 (1)
4 MAKE_FUNCTION 0
6 STORE_NAME 0 (0)
8 LOAD_NAME 1 (1)
10 LOAD_CONST 2 (2)
12 LOAD_NAME 0 (0)
14 LOAD_CONST 3 (3)
16 CALL_FUNCTION 1
18 FORMAT_VALUE 0
20 BUILD_STRING 2
22 CALL_FUNCTION 1
24 POP_TOP
26 LOAD_CONST 4 (4)
28 RETURN_VALUE
在反编译后的输出结果中,第一列代表字节码中每一条指令的偏移量 offset;第二列代表各条助记符 mnemonics 的名称,这些助记符可以很方便地帮助我们理解在后续的步骤中 Python 虚拟机要执行的事件;第三列则是每条指令的操作数 opargs。
同时,在字节码对应的十六进制表示中,每一位数字也分别代表了不同的助记符和操作数,我们可以直接通过打印出字节码的十六进制以查看其内容:
print(bytecode.hex())
64 00 64 01 84 00 5a 00 65 01 64 02 65 00 64 03 83 01 9b 00 9d 02 83 01 01 00 64 04 53 00
以上面反编译后的输出为例,在 offset == 0 的地方可以找到数字 64,即 LOAD_CONST 加载常量助记符对应的操作码 opcode,其后紧跟着的是它的操作数 opargs == 0;而指令第四行对应的 offset == 6,可以看到 STORE_NAME 助记符对应的操作码 opcode == 5a ,其操作数 opargs == 0;以此类推。
Python 的 opcode 模块提供了关于 Python 虚拟机中助记符和操作码的相关信息,也可以在源码的 Include/opcode.h 中找到相关定义:
import opcode
print(opcode.opname[0x64])
print(opcode.opname[0x5a])
print(opcode.opmap['LOAD_NAME'])
print(opcode.opmap['RETURN_VALUE'])
LOAD_CONST
STORE_NAME
101
83
1.3 编译原理
Python 编译器的实现和其他语言类似,包含了词法分析 Lexical,语法分析 Syntax Analysis 和语义分析 Semantic Analysis 等步骤,本文不再赘述编译原理的部分。
2 Python 虚拟机
类似于 x86-64, arm 平台和 Java 虚拟机,Python 虚拟机也是 基于栈的(Stack-Based),它的函数调用都是通过调用栈 call stack 和栈帧 stackframe 来实现的。
2.1 调用栈
调用栈是 CPU 寄存器中的一块内存区域,它是一种 FILO 的数据结构,可以进行插入或删除操作的一边称为栈顶,另一边则称为栈底;对于最常见的 x86-64 架构来说,栈地址空间是自顶向下(head down)增长的:
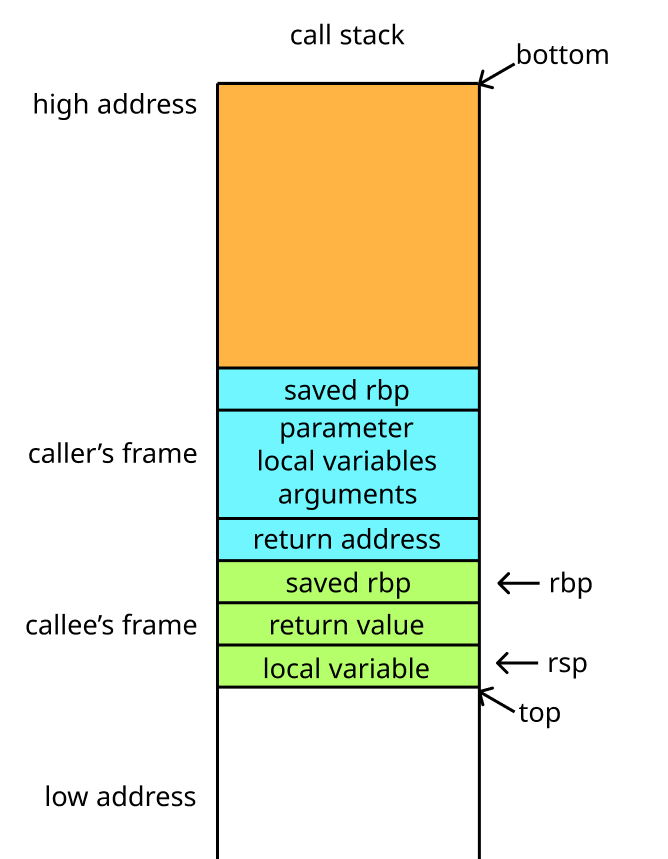
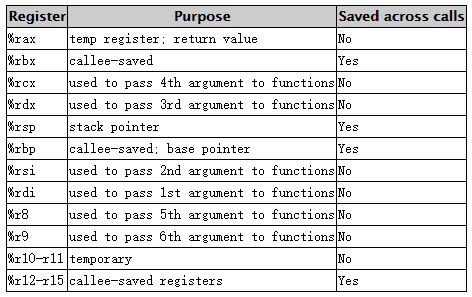
在 x86-64 平台下,它拥有 16 个通用寄存器 general-purpose registers,寄存器被集成在 CPU 芯片上,其中 rbp 寄存器保存当前栈帧的栈底(本次函数调用开始时的位置),rsp 寄存器保存当前栈帧的栈顶(函数运行时的当前位置),rbp 和 rsp 之间的空间则被称为本次函数调用的栈帧 stack frame;在每一次发生函数调用时,调用栈上都会维护一个独立的栈帧以存储函数返回值、参数、局部变量等信息;其他通用寄存器的功能如下。
栈相关的最常见操作有 push 和 pop,push 操作会将一个操作数插入栈顶,这包含了两个步骤,分别是先将 rsp 寄存器保存的地址减去 8,再将操作数写入到这个地址中;而 pop 则正好相反,它先从 rsp 寄存器存储的地址取出数据,写入到其他寄存器中,再对其地址加上 8。
以调试一个简单的 Swap 函数调用为例;本文使用的所有汇编语言都是 AT&T Syntax 的:
// main.cpp
#include <iostream>
using namespace std;
void Swap(int& a, int &b)
{
int c = a;
a = b;
b = c;
}
int main()
{
int a = 5, b = 9;
Swap(a, b);
cout << a << ' ' << b << endl;
return 0;
}
用 gdb 打开并在 main 函数处断点;在 main 函数栈帧中,会通过 movl 指令将两个常量拷贝到内存中:
$ g++ -g -O0 -o main main.cpp
$ gdb main
(gdb) b main
(gdb) r
(gdb) layout reg
> 0x400852 <main()+9> movl $0x5,-0x14(%rbp) # 将常量 9 保存在 rbp - 18 的位置
0x400859 <main()+16> movl $0x9,-0x18(%rbp) # 将常量 5 保存在 rbp - 14 的位置
在调用函数 Swap 前,会分别将两个参数存入 rdi 和 rsi 寄存器中:
0x400860 <main()+23> lea -0x18(%rbp),%rdx
0x400864 <main()+27> lea -0x14(%rbp),%rax
0x400868 <main()+31> mov %rdx,%rsi
0x40086b <main()+34> mov %rax,%rdi
> 0x40086e <main()+37> callq 0x40081d <Swap(int&, int&)>
(gdb) p *$rsi
$6 = 9
(gdb) p *$rdi
$7 = 5
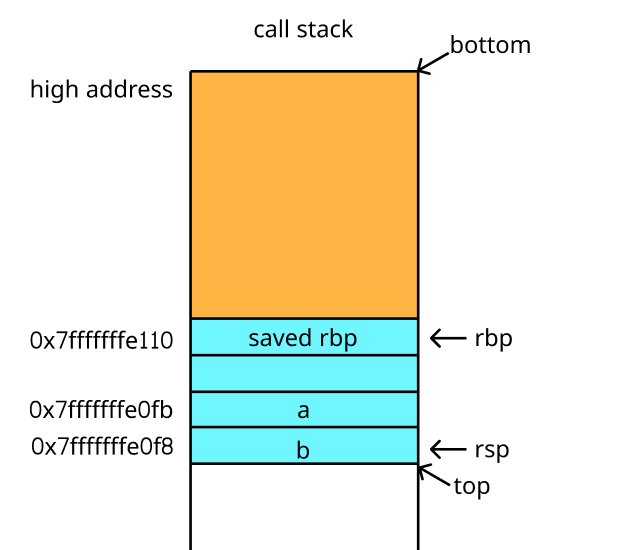
在 callq 指令处使用 stepi 进入到 Swap 函数中,此时 rbp 和 rsp 指针还分别指向 main 函数栈帧的底部和顶部,能够发现栈地址空间的确是向下增长的:
> 0x40086e <main()+37> callq 0x40081d <Swap(int&, int&)>
(gdb) si
> 0x40081d <Swap(int&, int&)> push %rbp
0x40081e <Swap(int&, int&)+1> mov %rsp,%rbp
rbp 0x7fffffffe110 0x7fffffffe110
rsp 0x7fffffffe0e8 0x7fffffffe0e8
此时栈帧结构大致如下:
执行接下来的 push 指令,将 rbp 的值存入栈顶,可以看到 rsp 的值发生了变化:
(gdb) ni
0x40081d <Swap(int&, int&)> push %rbp
> 0x40081e <Swap(int&, int&)+1> mov %rsp,%rbp
rbp 0x7fffffffe110 0x7fffffffe110
rsp 0x7fffffffe0e0 0x7fffffffe0e0
继续执行下一条 mov 指令,重置 rbp 的值,进入新的栈帧:
(gdb) ni
rbp 0x7fffffffe0e0 0x7fffffffe0e0
rsp 0x7fffffffe0e0 0x7fffffffe0e0
此时栈帧结构变成了如下:
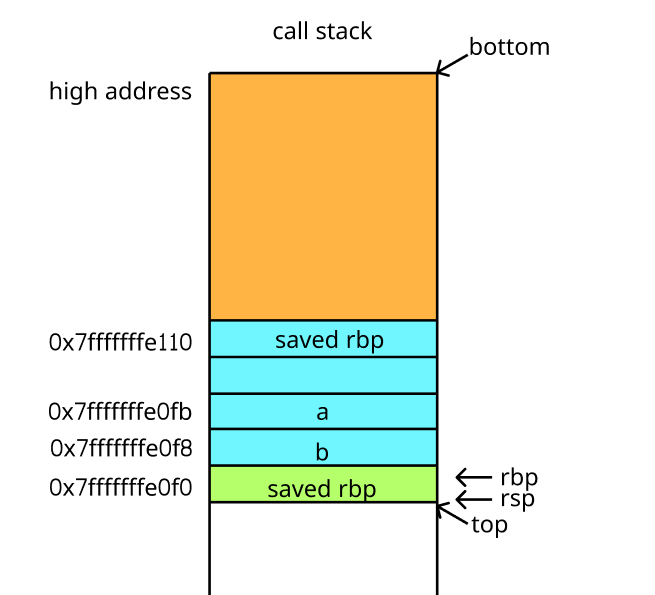
再经过一系列的 mov 指令操作,将 a 和 b 的值交换之后,执行下一条 pop 指令,将存储的上一个栈帧地址写入 rbp 中,同时修改 rsp;之后再执行 retq 指令即可继续运行 main 函数的下一条汇编指令了:
> 0x400847 <Swap(int&, int&)+42> pop %rbp
0x400848 <Swap(int&, int&)+43> retq
rbp 0x7fffffffe0e0 0x7fffffffe0e0
rsp 0x7fffffffe0e0 0x7fffffffe0e0
(gdb) ni
0x400847 <Swap(int&, int&)+42> pop %rbp
> 0x400848 <Swap(int&, int&)+43> retq
rbp 0x7fffffffe110 0x7fffffffe110
rsp 0x7fffffffe0e8 0x7fffffffe0e8
Python 中函数调用链和调用栈之间的关系也和 x86-64 平台类似,只不过是把代码块和栈帧分别进行了封装而已。
2.2 栈帧对象
Python 中的代码对象 PyCodeObject 本身只包含了字节码相关的信息,并不具备用于执行字节码所需要的上下文信息,因此需要引入栈帧对象 PyFrameObject,作为代码对象运行的容器,并用来模拟其他平台下的栈帧:
// cpython/Include/frameobject.h
struct _frame {
PyObject_VAR_HEAD
struct _frame *f_back; /* previous frame, or NULL */
PyCodeObject *f_code; /* code segment */
PyObject *f_builtins; /* builtin symbol table (PyDictObject) */
PyObject *f_globals; /* global symbol table (PyDictObject) */
PyObject *f_locals; /* local symbol table (any mapping) */
PyObject **f_valuestack; /* points after the last local */
PyObject *f_trace; /* Trace function */
int f_stackdepth; /* Depth of value stack */
char f_trace_lines; /* Emit per-line trace events? */
char f_trace_opcodes; /* Emit per-opcode trace events? */
/* Borrowed reference to a generator, or NULL */
PyObject *f_gen;
int f_lasti; /* Last instruction if called */
/* Call PyFrame_GetLineNumber() instead of reading this field
directly. As of 2.3 f_lineno is only valid when tracing is
active (i.e. when f_trace is set). At other times we use
PyCode_Addr2Line to calculate the line from the current
bytecode index. */
int f_lineno; /* Current line number */
int f_iblock; /* index in f_blockstack */
PyFrameState f_state; /* What state the frame is in */
PyTryBlock f_blockstack[CO_MAXBLOCKS]; /* for try and loop blocks */
PyObject *f_localsplus[1]; /* locals+stack, dynamically sized */
};
// cpython/Include/pyframe.h
typedef struct _frame PyFrameObject;
可以看到栈帧对象中大致包含了以下数据,它们构成了 Python 虚拟机执行当前栈帧所需要的所有上下文:
- 上一个运行的栈帧对象的指针
struct _frame *f_back;Python 虚拟机中运行的所有栈帧对象的*f_back共同组成调用栈结构,仅有初始栈帧有f_back == NULL; - 代码对象指针
PyCodeObject *f_code,它包含了当前运行栈帧所执行的字节码信息; - 代码对象执行期间的栈结构
PyObject **f_valuestack,在对字节码进行运算时,需要从栈顶读取数据,并将运算结果存储在栈顶,f_valuestack就是用来用来存储数据的栈结构,它的大小由对应的代码对象f_code的堆栈大小决定; - 代码对象执行期间使用的栈结构的深度
int f_stackdepth; - 上一条执行过的字节码指令
int f_lasti,类似于 rip 寄存器; - 内置命名空间、全局命名空间、局部命名空间的指针
PyObject *f_builtins,PyObject *f_globals,PyObject *f_locals,它们是用来实现 Python 中从符号到对象的映射的结构,一般用字典实现,暂不讨论; - 用于跟踪代码执行情况的函数指针
PyObject *f_trace和相关数据char f_trace_lines,char f_trace_opcodes,暂不讨论; - 用于执行生成器代码的数据
PyObject *f_gen,暂不讨论;
Python 在 sys 模块中提供了 _getframe 函数来获取栈帧对象;以一个简单的 Swap 函数为例,在最深层的函数调用处打印出栈帧对象的信息:
import sys
def Swap(a, b):
frame = sys._getframe()
while frame is not None:
print(f"frame:\t{frame}")
print(f"name:\t{frame.f_code.co_name}")
print(f"locals:\t{frame.f_locals.keys()}\n")
print(f"back:\t{frame.f_back}\n")
frame = frame.f_back
return b, a
def main():
a, b = 5, 9
a, b = Swap(a, b)
print(a, b)
if __name__ == "__main__":
main()
运行后可以观察到,在 Python 程序开始执行时会先创建一个叫做 module 的栈帧对象用于执行当前脚本中的代码;在每次函数调用的过程中,都会创建出一个新的栈帧对象,这些栈帧对象会使用 f_back 指针保存上一个执行栈帧的地址,并在之后调用其他函数的时候被压入栈顶:
$ python3 main.py
frame: <frame at 0x7fe37d7e5900, file '/main.py', line 36, code Swap>
name: Swap
locals: dict_keys(['a', 'b', 'frame'])
back: <frame at 0x7fe71ca65040, file '/main.py', line 46, code main>
frame: <frame at 0x7fe376115040, file '/main.py', line 46, code main>
name: main
locals: dict_keys(['a', 'b'])
back: <frame at 0x141f6f0, file '/main.py', line 50, code <module>>
frame: <frame at 0x1ade6f0, file '/main.py', line 50, code <module>>
name: <module>
locals: dict_keys(['__name__', '__doc__', '__package__', '__loader__', '__spec__', '__annotations__', '__builtins__', '__file__', '__cached__', 'sys', 'Swap', 'main'])
back: None
9 5
2.2.1 回收和分配
前文讨论过类型对象,从刚才获取栈帧对象的例子里能够看到通过 sys._getframe() 获取的 frame 对象的类型名为 frame,不难找到它的类型对象实际上是 PyFrame_Type,我们可以从类型对象初始化时使用的函数指针找到它的相关操作:
PyTypeObject PyFrame_Type = {
PyVarObject_HEAD_INIT(&PyType_Type, 0)
"frame",
sizeof(PyFrameObject),
sizeof(PyObject *),
(destructor)frame_dealloc, /* tp_dealloc */
0, /* tp_vectorcall_offset */
0, /* tp_getattr */
0, /* tp_setattr */
0, /* tp_as_async */
(reprfunc)frame_repr, /* tp_repr */
0, /* tp_as_number */
0, /* tp_as_sequence */
0, /* tp_as_mapping */
0, /* tp_hash */
0, /* tp_call */
0, /* tp_str */
PyObject_GenericGetAttr, /* tp_getattro */
PyObject_GenericSetAttr, /* tp_setattro */
0, /* tp_as_buffer */
Py_TPFLAGS_DEFAULT | Py_TPFLAGS_HAVE_GC,/* tp_flags */
0, /* tp_doc */
(traverseproc)frame_traverse, /* tp_traverse */
(inquiry)frame_tp_clear, /* tp_clear */
0, /* tp_richcompare */
0, /* tp_weaklistoffset */
0, /* tp_iter */
0, /* tp_iternext */
frame_methods, /* tp_methods */
frame_memberlist, /* tp_members */
frame_getsetlist, /* tp_getset */
0, /* tp_base */
0, /* tp_dict */
};
其中对栈帧对象进行析构的函数是 frame_dealloc,此处省略了部分代码:
#define PyFrame_MAXFREELIST 200
static void _Py_HOT_FUNCTION
frame_dealloc(PyFrameObject *f)
{
// ...
Py_XDECREF(f->f_back);
Py_DECREF(f->f_builtins);
Py_DECREF(f->f_globals);
Py_CLEAR(f->f_locals);
Py_CLEAR(f->f_trace);
PyCodeObject *co = f->f_code;
if (co->co_zombieframe == NULL) {
co->co_zombieframe = f;
}
else {
struct _Py_frame_state *state = get_frame_state();
#ifdef Py_DEBUG
// frame_dealloc() must not be called after _PyFrame_Fini()
assert(state->numfree != -1);
#endif
if (state->numfree < PyFrame_MAXFREELIST) {
++state->numfree;
f->f_back = state->free_list;
state->free_list = f;
}
else {
PyObject_GC_Del(f);
}
}
Py_DECREF(co);
Py_TRASHCAN_SAFE_END(f)
}
struct _Py_frame_state {
PyFrameObject *free_list;
/* number of frames currently in free_list */
int numfree;
};
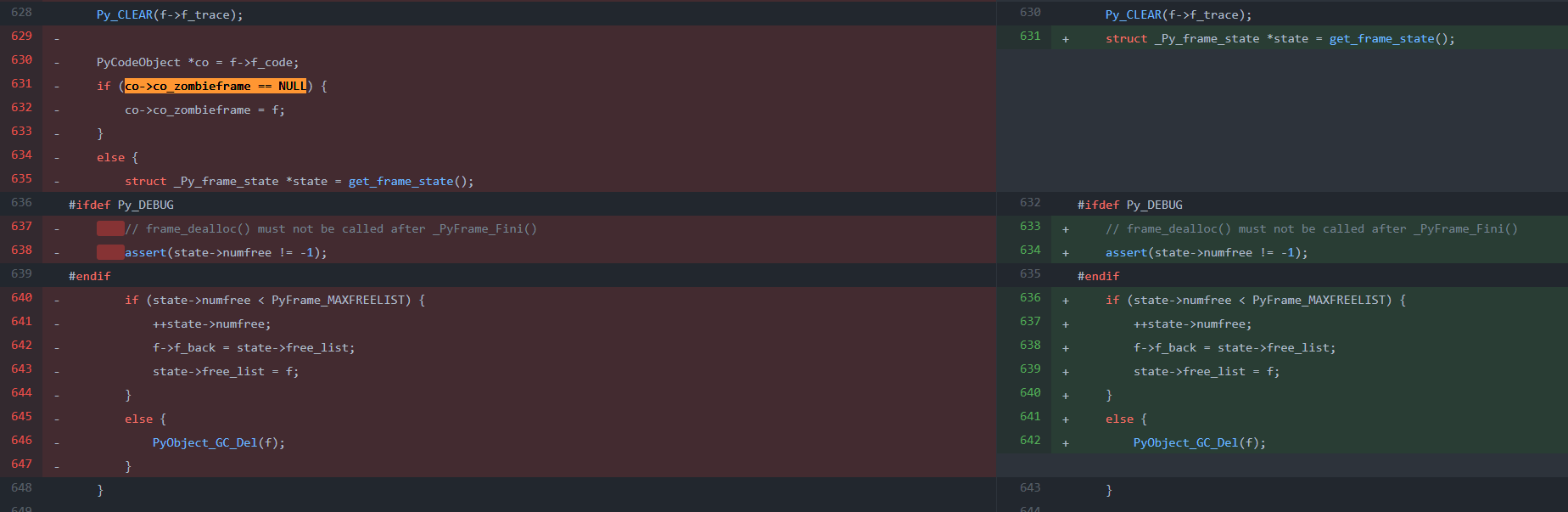
这是一个使用非常高频的函数(几乎每一次栈帧退出时都会调用),因此采用了一些策略来进行优化以降低调用函数的开销;一种是在首次进行栈帧对象 f 的回收时会先判断栈帧对象关联的代码对象 co 的成员指针 co_zombieframe 是否为空 if (co->co_zombieframe == NULL);如果是,则会将该栈帧对象 f 保存在代码对象的这个指针中 co->co_zombieframe = f,这样的话在下一次执行相同的代码对象 co 时,就无需再次重新进行栈帧对象 f 的内存分配(只要代码对象 co 不因为引用计数降低为 0 而被 gc);对于栈帧对象来说,仅有 ob_type, ob_size, f_code, f_valuestack 几个成员变量会保留原有的值,因为这些成员变量与其他对象没有关联,而 f_locals, f_trace, f_exc_type 等指针依然会被通过 Py_CLEAR 置为 NULL,因为通过这些指针关联的对象可能会通过其他途径被回收,从而导致悬空指针的问题。
另一个优化策略是当代码对象 co 的成员指针 co->co_zombieframe 不为空,即再次执行相同栈帧时,会使用由 Python 线程维护的缓存栈帧链表 state->free_list 将栈帧对象存储下来,此时如果有新的栈帧对象被定义的话,可以直接从缓存栈帧链表 state->free_list 中获取一个已经分配内存的栈帧对象直接赋值并使用,以达到减少分配和回收内存的效果。此处可以结合分配栈帧的 frame_alloc 函数来看:
static inline PyFrameObject*
frame_alloc(PyCodeObject *code)
{
// ...
if (state->free_list == NULL)
{
f = PyObject_GC_NewVar(PyFrameObject, &PyFrame_Type, extras);
if (f == NULL) {
return NULL;
}
}
else {
#ifdef Py_DEBUG
// frame_alloc() must not be called after _PyFrame_Fini()
assert(state->numfree != -1);
#endif
assert(state->numfree > 0);
--state->numfree;
f = state->free_list;
state->free_list = state->free_list->f_back;
if (Py_SIZE(f) < extras) {
PyFrameObject *new_f = PyObject_GC_Resize(PyFrameObject, f, extras);
if (new_f == NULL) {
PyObject_GC_Del(f);
return NULL;
}
f = new_f;
}
_Py_NewReference((PyObject *)f);
}
// ...
}
可以看到在进行栈帧对象的分配时,会优先判断缓存栈帧链表 state->free_list 是否为空,不为空的话则会从其链表头部取出一个已经分配好内存的栈帧对象,对其赋值并使用。
这项优化(将未使用的栈帧对象保存在缓存栈帧链表中,并在创建其他栈帧对象时重复利用)与前者(在栈帧退出时将栈帧对象随代码对象保存下来,在执行相同代码对象时直接使用)的做法有些冲突,因此前者在最新的 PR 26076 中已经被移除了。
2.3 运行过程
2.3.1 调用流程
Python 的 main 函数在 cpython/Programs/python.c 文件中,这部分实现比较简单,其调用链可以总结如下:
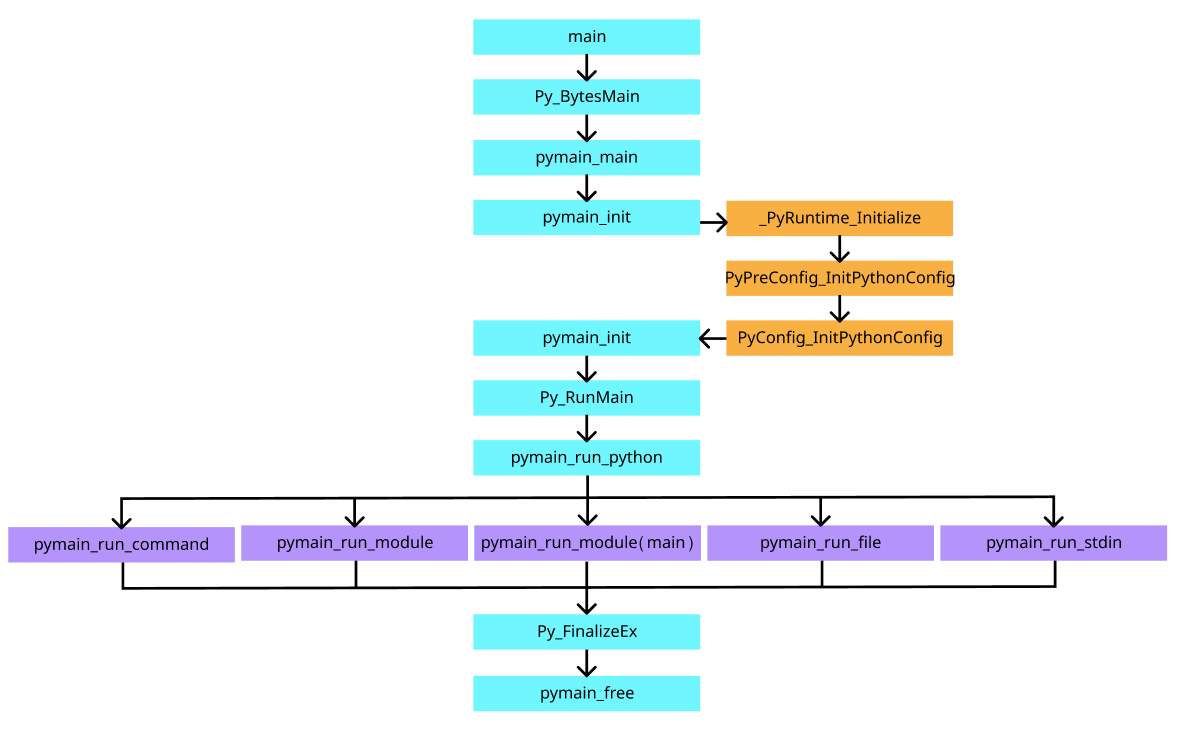
从调用链中可以看到,在真正执行 Python 代码之前,会先读取配置并进行初始化,这些配置会被保存到 cpython/Include/cpython/initconfig.h 文件定义的 PyConfig 结构体中,这个结构体包含了 Python 运行时的环境变量,运行模式等信息;而调用链中 pymain_run_python 函数后的五个分支就分别代表了 Python 通过命令行、文件、标准输入等方式运行的五种模式,但无论是那种模式,最终都会通过调用 run_eval_code_obj 以及 PyEval_EvalCode 函数来执行编译后的代码对象,后者就是 Python 虚拟机执行指令的入口之一。
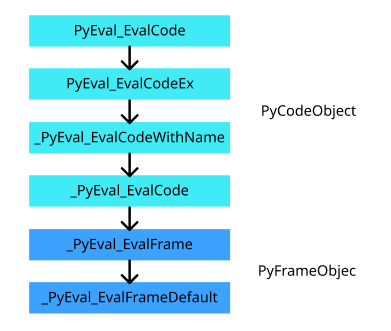
2.3.2 运行栈帧
Python 虚拟机中执行指令的入口有 PyEval_EvalCode 和 PyEval_EvalCodeEx,前者相对于后者省略了部分参数,仅将必须的代码对象,全局变量和局部变量作为参数传入,其他参数均设为 NULL。
// cpython/Python/eval.h
PyAPI_FUNC(PyObject *) PyEval_EvalCode(PyObject *, PyObject *, PyObject *);
PyAPI_FUNC(PyObject *) PyEval_EvalCodeEx(PyObject *co,
PyObject *globals,
PyObject *locals,
PyObject *const *args, int argc,
PyObject *const *kwds, int kwdc,
PyObject *const *defs, int defc,
PyObject *kwdefs, PyObject *closure);
// cpython/Python/ceval.c
PyObject *
PyEval_EvalCode(PyObject *co, PyObject *globals, PyObject *locals)
{
return PyEval_EvalCodeEx(co,
globals, locals,
(PyObject **)NULL, 0,
(PyObject **)NULL, 0,
(PyObject **)NULL, 0,
NULL, NULL);
}
而 PyEval_EvalCodeEx 实际上会调用 _PyEval_EvalCodeWithName 函数,进行参数个数和类型的校验,以及线程状态的检查,并最终调用了 _PyEval_EvalCode 函数:
PyObject *
_PyEval_EvalCodeWithName(PyObject *_co, PyObject *globals, PyObject *locals,
PyObject *const *args, Py_ssize_t argcount,
PyObject *const *kwnames, PyObject *const *kwargs,
Py_ssize_t kwcount, int kwstep,
PyObject *const *defs, Py_ssize_t defcount,
PyObject *kwdefs, PyObject *closure,
PyObject *name, PyObject *qualname)
{
PyThreadState *tstate = _PyThreadState_GET();
return _PyEval_EvalCode(tstate, _co, globals, locals,
args, argcount,
kwnames, kwargs,
kwcount, kwstep,
defs, defcount,
kwdefs, closure,
name, qualname);
}
PyObject *
PyEval_EvalCodeEx(PyObject *_co, PyObject *globals, PyObject *locals,
PyObject *const *args, int argcount,
PyObject *const *kws, int kwcount,
PyObject *const *defs, int defcount,
PyObject *kwdefs, PyObject *closure)
{
return _PyEval_EvalCodeWithName(_co, globals, locals,
args, argcount,
kws, kws != NULL ? kws + 1 : NULL,
kwcount, 2,
defs, defcount,
kwdefs, closure,
NULL, NULL);
}
_PyEval_EvalCode 函数会对代码对象参数 PyCodeObject *co 及其参数进行常规检查,并初始化栈帧对象 PyFrameObject *f,并调用 _PyEval_EvalFrame:
// cpython/Python/ceval.c
PyObject *
_PyEval_EvalCode(PyThreadState *tstate,
PyObject *_co, PyObject *globals, PyObject *locals,
PyObject *const *args, Py_ssize_t argcount,
PyObject *const *kwnames, PyObject *const *kwargs,
Py_ssize_t kwcount, int kwstep,
PyObject *const *defs, Py_ssize_t defcount,
PyObject *kwdefs, PyObject *closure,
PyObject *name, PyObject *qualname)
{
PyObject *retval = NULL;
/* Create the frame */
PyFrameObject *f = _PyFrame_New_NoTrack(tstate, co, globals, locals);
if (f == NULL) {
return NULL;
}
PyObject **fastlocals = f->f_localsplus;
PyObject **freevars = f->f_localsplus + co->co_nlocals;
// ...
retval = _PyEval_EvalFrame(tstate, f, 0);
fail: /* Jump here from prelude on failure */
/* decref'ing the frame can cause __del__ methods to get invoked,
which can call back into Python. While we're done with the
current Python frame (f), the associated C stack is still in use,
so recursion_depth must be boosted for the duration.
*/
if (Py_REFCNT(f) > 1) {
Py_DECREF(f);
_PyObject_GC_TRACK(f);
}
else {
++tstate->recursion_depth;
Py_DECREF(f);
--tstate->recursion_depth;
}
return retval;
}
_PyEval_EvalFrame 函数调用了一个函数指针,这个指针是随 Python 解释器初始化的:
// cpython/Python/internal/pycore_ceval.h
static inline PyObject*
_PyEval_EvalFrame(PyThreadState *tstate, PyFrameObject *f, int throwflag)
{
return tstate->interp->eval_frame(tstate, f, throwflag);
}
// cpython/Python/pystate.c
PyInterpreterState *
PyInterpreterState_New(void)
{
// ...
interp->eval_frame = _PyEval_EvalFrameDefault;
// ...
}
_PyEval_EvalFrameDefault 是整个调用链的终点,它的函数主体是一个循环,不断地读入字节码,并通过 switch 语句判断其类型并执行,
PyObject* _Py_HOT_FUNCTION
_PyEval_EvalFrameDefault(PyThreadState *tstate, PyFrameObject *f, int throwflag)
{
_Py_EnsureTstateNotNULL(tstate);
// ...
main_loop:
for (;;) {
opcode = _Py_OPCODE(*next_instr);
switch (opcode) {
case TARGET(LOAD_CONST): {
PREDICTED(LOAD_CONST);
PyObject *value = GETITEM(consts, oparg);
Py_INCREF(value);
PUSH(value);
FAST_DISPATCH();
// ...
}
// ...
这就是整个调用和运行栈帧对象的过程了,整理如下:
2.3.3 调试
最后以 [1.2](#1.2 字节码) 节的 test.py 代码为例,简单地用 gdb 来进行 _PyEval_EvalFrameDefault 函数中逐个字节码指令的调试:
$ gdb -ex r --args python3 test.py
(gdb) b _PyEval_EvalFrameDefault
Breakpoint 1 at 0x41fa90: file Python/ceval.c, line 919.
(gdb) r
(gdb) n
# ...
如果有对应版本的源码文件的话也可以直接断点在 switch (opcode) { 所在的行数,这里我们不断地往后执行直到这一行之后:
(gdb) layout split
1487 case TARGET(LOAD_CONST): {
1488 PREDICTED(LOAD_CONST);
> 1489 PyObject *value = GETITEM(consts, oparg);
1490 Py_INCREF(value);
1491 PUSH(value);
1492 FAST_DISPATCH();
1493 }
(gdb) p opcode
$1 = 100
(gdb) p oparg
$2 = 0
可以看到在执行 LOAD_CONST 助记符时,其对应的 opcode 的十六进制表示为64,十进制表示为 100,LOAD_CONST 首先获取了 oparg 的值,并填入到栈顶;
2343 case TARGET(STORE_NAME): {
> 2344 PyObject *name = GETITEM(names, oparg);
2345 PyObject *v = POP();
2346 PyObject *ns = f->f_locals;
2347 int err;
2348 if (ns == NULL) {
2349 _PyErr_Format(tstate, PyExc_SystemError,
2350 "no locals found when storing %R", name);
2351 Py_DECREF(v);
2352 goto error;
2353 }
2354 if (PyDict_CheckExact(ns))
2355 err = PyDict_SetItem(ns, name, v);
2356 else
2357 err = PyObject_SetItem(ns, name, v);
2358 Py_DECREF(v);
2359 if (err != 0)
2360 goto error;
2361 DISPATCH();
2362 }
STORE_NAME 也是类似的,它从栈顶取出一个数值,并存储在局部命名空间中;
2828 case TARGET(BUILD_MAP): {
2829 Py_ssize_t i;
> 2830 PyObject *map = _PyDict_NewPresized((Py_ssize_t)oparg);
2831 if (map == NULL)
2832 goto error;
2833 for (i = oparg; i > 0; i--) {
2834 int err;
2835 PyObject *key = PEEK(2*i);
2836 PyObject *value = PEEK(2*i - 1);
2837 err = PyDict_SetItem(map, key, value);
2838 if (err != 0) {
2839 Py_DECREF(map);
2840 goto error;
2841 }
2842 }
2843
2844 while (oparg--) {
2845 Py_DECREF(POP());
2846 Py_DECREF(POP());
2847 }
2848 PUSH(map);
2849 DISPATCH();
2850 }
(gdb) p opcode
$9 = 105
(gdb) p oparg
$10 = 0
BUILD_MAP 稍微复杂一些,它会构造一个 Python 中的字典对象(源码中 PyDictObject 结构体的实例对象,用哈希表实现),并不断地从栈帧上获取 key 和 value 插入到字典中;
2312 case TARGET(LOAD_BUILD_CLASS): {
2313 _Py_IDENTIFIER(__build_class__);
2314
> 2315 PyObject *bc;
2316 if (PyDict_CheckExact(f->f_builtins)) {
2317 bc = _PyDict_GetItemIdWithError(f->f_builtins, &PyId___build_class__);
2318 if (bc == NULL) {
2319 if (!_PyErr_Occurred(tstate)) {
2320 _PyErr_SetString(tstate, PyExc_NameError,
2321 "__build_class__ not found");
2322 }
2323 goto error;
2324 }
2325 Py_INCREF(bc);
2326 }
2327 else {
2328 PyObject *build_class_str = _PyUnicode_FromId(&PyId___build_class__);
2329 if (build_class_str == NULL)
2330 goto error;
2331 bc = PyObject_GetItem(f->f_builtins, build_class_str);
2332 if (bc == NULL) {
2333 if (_PyErr_ExceptionMatches(tstate, PyExc_KeyError))
2334 _PyErr_SetString(tstate, PyExc_NameError,
2335 "__build_class__ not found");
2336 goto error;
2337 }
2338 }
2339 PUSH(bc);
2340 DISPATCH();
2341 }
(gdb) p opcode
$11 = 71
(gdb) p oparg
$12 = 0
LOAD_BUILD_CLASS 则会从内置命名空间中通过哈希方法找到函数指针,并插入栈顶;
其他的字节码指令还有很多,都可以通过阅读源码或者使用 gdb 调试的方法找到其实际执行的代码;相比于汇编指令,字节码指令实际上代表了由许多行代码组成的功能,而 Python 虚拟机则是通过字节码指令模拟出了对汇编指令的执行过程。