Prometheus 入门
Prometheus 是一个开源的监控解决方案,也是云原生基金会 CNCF 的毕业项目,它能够提供指标数据的采集、存储、查询、告警等功能。本文主要介绍 Prometheus 的基础概念和应用中需要注意的一些问题。
1 监控系统
1.1 监控模式
监控系统执行监控检查的模式有两种,分别是 pull 和 push。Prometheus 采用了 pull 模式进行数据收集,同时也支持使用 Pushgateway 的 push 模式进行数据中转。
pull 方式的特点是有拉取间隔,不能及时获取数值的变化,因此需要进一步的数据处理;它的优点是在告警时可以按照策略分片,仅拉取需要的数据,并且支持聚合场景;缺点是监控的数据量庞大,对存储有较高的要求,切需要考虑数据的冷热分离。
push 方式的特点是由服务主动将数据推向监控系统,实时性更高;它的缺点是推送数据的不可预知性,因为当大量数据被推送到监控系统时,数据的缓存和解析会消耗大量资源,此时如果因为网络原因数据的收发没有得到确认,很容易产生数据的重发和重复,因此需要进行去重等操作。
pull 模式在云原生环境中更有优势,因为我们可以通过服务发现对所有需要进行监控的节点进行统一的数据拉取,如果使用 push 模式则需要在每个被监控的服务中部署上报数据的客户端,并配置监控服务器的信息,这会加大部署的难度。
1.2 Prometheus
Prometheus 是一套开源的数据采集与监控框架,可以做后台服务器的监控告警,此处用来采集被测服务的性能指标数据,包括CPU占用比率、内存消耗、网络IO等。
特点
Prometheus 最主要的特点有 4 个:
- 通过 PromQL 实现多维度数据模型的灵活查询;这使得监控指标可以关联到多个标签,并对时间序列进行切片和切块,以支持各种查询和告警场景
- 定义了开放指标数据的标准,可以方便地自定义探针(exporter)
- 利用 Pushgateway 组件可以以 push 的方式接收监控数据
- 提供了容器化版本
架构
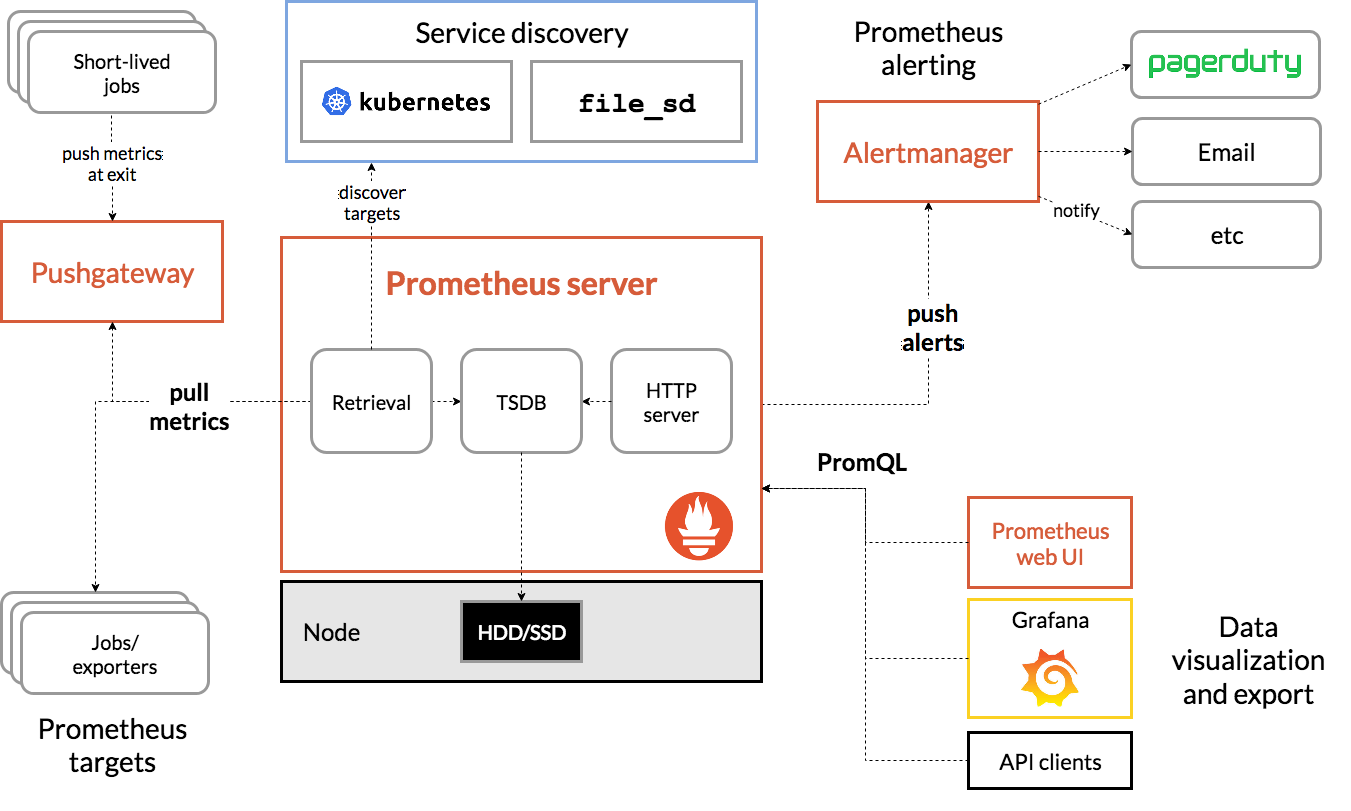
Prometheus 的架构主要由以下部分组成:
Prometheus Server
Prometheus 服务器主要包含了使用 pull 模式抓取监控数据,通过本地存储(本地磁盘)和远程存储(OpenTSDB, InfluxDB, ElasticSearch 等)保存数据,使用 PromQL 查询数据三大功能。
PromQL (Prometheus Query Language) 是 Prometheus 内置的数据查询语言,提供了对时间序列数据的查询,聚合和逻辑运算等操作的支持,被广泛地应用在数据的查询,可视化和告警中。关于 PromQL 的相关操作可以参考 探索PromQL。
Pushgateway
Pushgateway 是用来实现 push 模式监控的组件,一般应用于短作业,批处理作业,或当服务与 Prometheus 服务器之间有网络隔离时;它的主要问题是存在单点故障,一个 Pushgateway 的宕机会导致所有被推送到这个 Pushgateway 上的数据的丢失,如果使用多个 Pushgateway 实例组成的集群,那么每一次数据推送只会被分发到单个实例上,但 Prometheus Server 每次会在所有的 Pushgateway 实例上进行数据采集,这会导致数据错乱,目前官方对此并没有解决方案,一个比较好的开源方案是使用动态一致性哈希 + 基于 consul 的 service check;除此之外,Pushgateway 不会自动删除任何指标数据,即使在进行过 push 操作的 pod 被销毁之后,其上报的所有数据仍然残留在 Pushgateway 中,需要手动。
Job/Exporter
Job 和 Exporter 都是 Prometheus 的 target 监控对象;exporter 的机制是将监控数据暴露出来,Prometheus 对这些指标进行采集;每个 exporter 需要单独维护,如果数量过多可以考虑使用 Telegraf 进行统一管理。
Service Discovery
相比于读取文件配置,在云原生和容器环境下被监控实例都是会动态变化的,而通过服务发现,我们可以在很方便地获取需要被检控的 target 的实例信息;服务发现中的 relabeling 机制可以从 target 实例中获取元标签数据,从而对不同开发环境进行区分。
Alertmanager
Prometheus 将数据采集和告警分离成了两个模块,告警模块叫做 Alertmanager,它是独立于 Prometheus 的一个组件,需要单独部署,多个 Alertmanager 可以配置为一个集群来避免单点问题。报警规则被配置在 Prometheus Servers 上,产生告警信息时会通知 AlertManger,AlertManager 会通过 silencing, inhibition 等方式聚合,并通过 email、PagerDuty、HipChat、Slack 等方式发送告警提示。
Dashboard
Web UI, Grafana, API Client 等统称为 Dashboard。
局限性
- Prometheus 是基于 metrics 的系统,不适合存储日志
- Prometheus 认为只有近期的数据才需要被查询,因此本地存储只会保存短期数据;TB 级以上的历史数据需要搭配 OpenTSDB 等远端存储使用
- Prometheus 的集群方案有 federation 和开源的 Thanos,但都存在各种细节上的技术问题(如耗尽 CPU 和机器资源),其成熟度都比不上在时序数据库中排名第一的 InfluxDB
2 数据模型
2.1 时序数据
Prometheus 存储的是时序数据,即由名称 name,标签 label 与值 value 定义的指标 metric;Prometheus 中所有的指标都是时序数据,并以名称和标签进行区分;具有相同名称和标签的数据属于相同时序,这些时序数据拥有不同的时间戳。
指标命名
指标的名字由 ASCII 字符,数字,下划线,以及冒号组成,且满足正则表达式 [a-zA-Z0-9_:]*, 其命名应该具有语义化,用于表示一个可以度量的指标,例如 http_requests_total;时序的标签可以用于区分具体不同的方法和参数变量,例如 http_requests_total{method="POST"}。
一个 metric 的命名应该具有以下几个特点:
以命名空间或应用名称作为前缀,避免不通作用域的相同名称产生冲突,例如 prometheus_notifications_total, http_request_duration_seconds
以基本单位(秒,米,字节,个数等)作为后缀,例如 http_requests_total, node_memory_usage_bytes
将所有标签的共同逻辑部分抽离作为名称,将可变量作为标签的一部分
指标类型
指标是整个监控系统的核心,Prometheus 中的指标类型 Metrics Type 有以下四种:
- Counter
Counter 是只增不减的计数器,一般用于记录服务请求,返回或错误的总量,它会在程序重启时被重置为 0。例如 Prometheus Server 中 http_requests_total 表示当前处理的 http 请求总数。
为了能够直观地展示指标数据计数的变化情况,一般需要计算 Counter 数据的增长速率,建议 PromQL 中的 rate, topk, increase, irate 等函数使用。
- Gauge
Gauge 表示可以任意变化的快照数据,一般用于记录内存使用率,CPU 温度,程序中的 goroutine 数量等。例如 Prometheus Server 中 go_goroutines 表示当前 goroutines 的数量。
Gauge 经常结合 PromQL 中的最大值 max,最小值min,总和 sum 函数,或基于线性回归的时间序列预测函数 predict_linear ,获取指标在一段时间内的变化情况的 delta 等函数使用。
- Histogram
Histogram 用于对一定时间范围内的数据进行采样,记录各个桶中的数据个数。例如 Prometheus Server 中 prometheus_local_storage_series_chunks_persisted 表示每个时间序列需要存储的 chunks 数量,我们可以使用 histogram_quantile 计算待持久化的数据的分位数 quantile 数据。
- Summary
Summary 和 Histogram 类似,也用于表示一段时间范围内的数据采样结果,它直接存储了分位数 quantile 数据(通过客户端计算),而非根据统计区间计算。对于分位数的计算,Summary 在通过 PromQL 进行查询时有更好的性能表现,而 Histogram 则会消耗更多的资源。反之,对于客户端而言,Histogram 消耗的资源更少。
2.2 数据采集
Prometheus server 的数据采集基于 Pull 模型,其工作流程大致为 Prometheus server 会定期地从 exporter 上通过 HTTP 接口获取 metrics 结构的数据,并进行存储,如果 Prometheus Server 与 Exporter 不能够直接进行通信,那么我们可以将 exporter 上的数据推送到 Pushgateway 上,并让 Prometheus Server 从 PushGateway 上获取数据。
术语
Exporter:所有向 Prometheus server 提供数据的程序都可以被称为 exporter,Prometheus server 会周期性地从 exporter 提供的HTTP 服务 URL 拉取数据,我们只需要在 Prometheus server 的配置文件 /etc/prometheus/prometheus.yml 中添加一个target,并重启服务即可定位到 exporter 并拉取数据。
Instance:任意一个独立的数据源 target 都可以被称为 Instance 实例,它是用来提供数据的最小单位。
Job:包含相同类型的实例的集合叫做 Job,例如在 k8s 集群上被复制出的可弹性伸缩的一组 pod 中的相同进程。
2.3 Pushgateway
由于 Prometheus server 采用 pull 模式获取数据,如果 Prometheus server 和 exporter 由于不在一个子网环境或由于防火墙原因导致两者无法直接通信,或在我们需要将多个 exporter 的数据汇总到一起时,我们可以主动将数据推送到 Pushgateway 上,间接地进行数据采集;但它的弊端也很明显,那就是单点故障,如果唯一的 Pushgateway 出现不可用的情况,那么所有的数据都无法被 Prometheus server 获取。
Pushgateway 不需要任何配置,直接启动 docker image 后即可使用。
docker pull prom/pushgateway
docker run -d -p 9091:9091 prom/pushgateway
启动好 Pushgateway 之后,需要在 Prometheus server 的静态配置中添加 Pushgateway:
docker exec -it --user root f257794e5e3d sh
vi /etc/prometheus/prometheus.yml
scrape_configs:
- job_name: "pushgateway"
static_configs:
- targets: ["ip:port"]
修改配置后,发送信号给 Prometheus Server 使其加载最新的配置:
kill -HUP $pid
默认情况下,Pushgateway 将所有数据存储在内存中,因此一旦 Pushagateway 服务因为故障而停止运行,那么所有尚未被 Prometheus server 获取的数据都将会丢失,为此可以在启动 Pushgateway 服务时通过指定 persistence.file 参数将数据持久化:
pushgateway --persistence.file="/tmp/pushgateway_persist"
默认情况下,文件每五分钟持久化写入一次,我们可以通过修改 persistence.interval 参数来进行调整。
推送数据
向 Pushgateway 推送数据时可以使用 PUT 和 POST 两种方法,其中 PUT 会将实例中的所有 metrics 替换为新推送的 metrics,而 POST 则只会将 name 相同 metrics 替换(前提是这部分数据在相同的 job/instance 下);
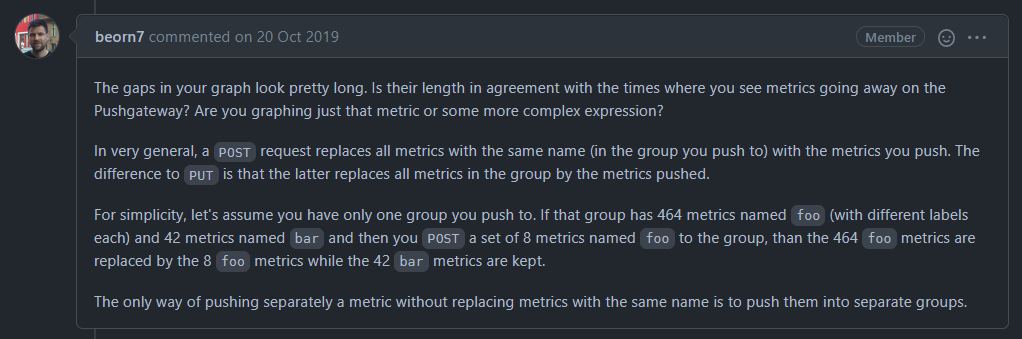
假设将要进行推送的数据如下:
$ cat req1.txt
# TYPE foo GAUGE
foo{id="1"} 1
foo{id="2"} 2
foo{id="3"} 3
# TYPE bar GAUGE
bar{id="11"} 11
将其推送到 Pushgateway 上并检查:
$ curl -X POST --data-binary @req1.txt localhost:9091/metrics/job/test
$ curl localhost:9091/metrics | grep test
bar{id="11",instance="",job="test"} 11
foo{id="1",instance="",job="test"} 1
foo{id="2",instance="",job="test"} 2
foo{id="3",instance="",job="test"} 3
使用 POST 方法推送另一组数据:
$ cat req2.txt
# TYPE foo GAUGE
foo{id="4"} 4
foo{id="5"} 5
$ curl -X POST --data-binary @req2.txt localhost:9091/metrics/job/test
$ curl localhost:9091/metrics | grep test
bar{id="11",instance="",job="test"} 11
foo{id="4",instance="",job="test"} 4
foo{id="5",instance="",job="test"} 5
可以看到原有的 name 为 foo 的数据都被覆盖了;
使用 PUT 方法推送第二组数据:
$ curl -X PUT --data-binary @req2.txt localhost:9091/metrics/job/test
$ curl localhost:9091/metrics | grep test
foo{id="4",instance="",job="test"} 4
foo{id="5",instance="",job="test"} 5
可以看到原有的所有数据(包括 name 不同的 bar 数据)都被覆盖了。
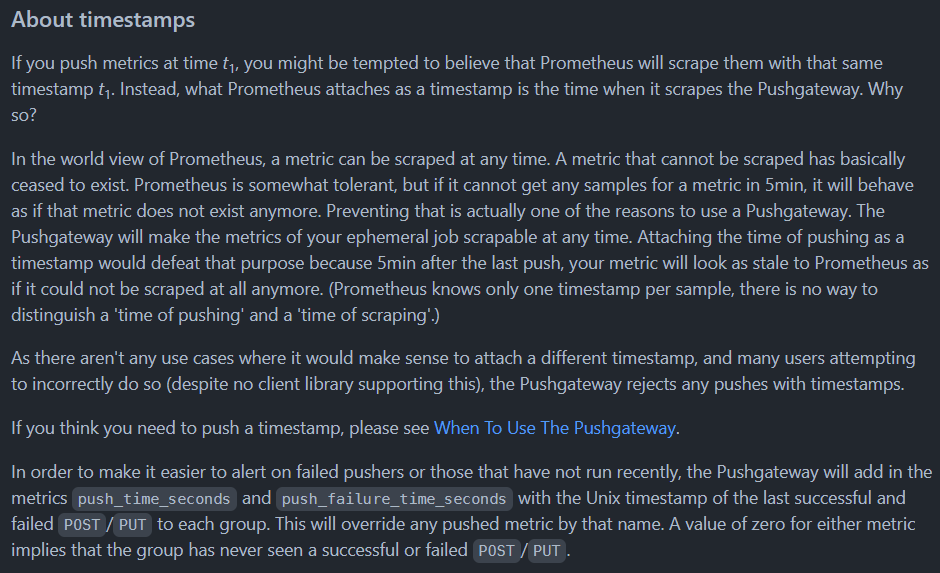
推送不能包含时间戳
Prometheus pull 数据时不会采集与当前时间差在 5 分钟以上的数据,官方认为 pushgateway 一般用在临时任务和批处理作业上,为了防止这些任务因为存在的时间不够长导致 Prometheus 还没来得及 pull 数据就结束了,所以不允许在向 pushgateway 推送数据时带上时间戳。
删除数据
如果想要删除 Pushgateway 上特定的数据,可以使用官方提供的 http API:
- 删除特定 job 和 instance 的所有数据:
curl -X DELETE http://pushgateway.example.org:9091/metrics/job/some_job/instance/some_instance
- 删除特定 job ,且 instance="" 下的所有数据,注意这不会删除其他 instance 的数据:
curl -X DELETE http://pushgateway.example.org:9091/metrics/job/some_job
- 删除一个实例上的所有数据(需要在启动时加上参数
--web.enable-admin-api才能用):
curl -X PUT http://pushgateway.example.org:9091/api/v1/admin/wipe